Rev Bras Oftalmol.2026;85:e0009
Análise comparativa de desempenho entre ChatGPT, Scholar GPT e DeepSeek em provas teóricas do Conselho Brasileiro de Oftalmologia 2022
DOI: 10.37039/1982.8551.20260009
RESUMO
Objetivo:
Realizar uma análise comparativa do desempenho de três modelos de inteligência artificial (ChatGPT, Scholar GPT e DeepSeek) na resolução das provas teóricas I e II do Título de Especialista em Oftalmologia de 2022.
Métodos:
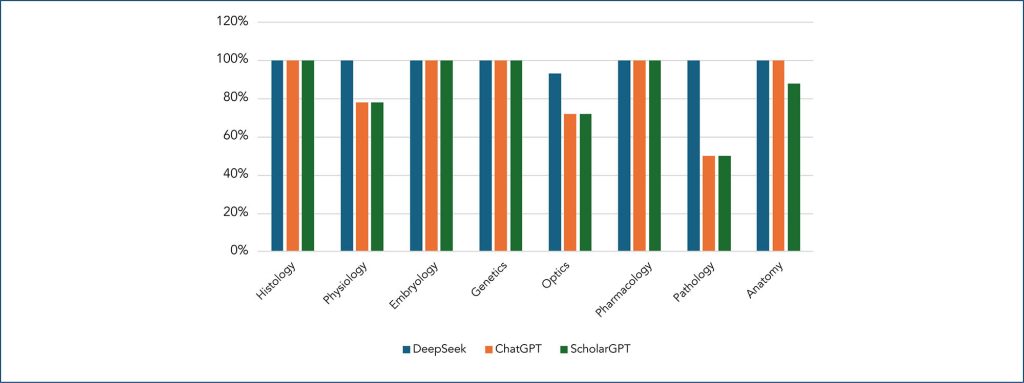
Foram analisadas 46 questões válidas da prova teórica I e 122 da prova teórica II, após a exclusão de 7 questões anuladas. Os modelos foram configurados para operar em condições padronizadas, e suas respostas foram comparadas aos gabaritos oficiais.
Resultados:
O DeepSeek apresentou o melhor desempenho, com taxa de acertos de 97,8% na prova teórica I e 81,9% na prova teórica II, superando consistentemente os demais modelos em todas as áreas de conhecimento. O ChatGPT obteve desempenho intermediário, enquanto o Scholar GPT teve a menor taxa de acertos.
Conclusão:
Os resultados evidenciam a superioridade do DeepSeek em tarefas altamente especializadas, reforçando a relevância de modelos de Inteligência Artificial treinados para domínios técnicos específicos. No entanto, todos os modelos demonstraram limitações em questões mais complexas, ressaltando a necessidade de complementação com supervisão humana para aplicações críticas.
Palavras-chave: ChatGPT; DeepSeek; Educação Médica; Inteligência artificial; Inteligência artificial generativa; Oftalmologia; Scholar GPT