Rev Bras Oftalmol.2026;85:e0009
Comparative performance analysis of ChatGPT, Scholar GPT, and DeepSeek of the Conselho Brasileiro de Oftalmologia 2022 theoretical exams
DOI: 10.37039/1982.8551.20260009
ABSTRACT
Objective:
This study presents a comparative analysis of the performance of three artificial intelligence models (ChatGPT, Scholar GPT, and DeepSeek) in solving the CBO 2022 theoretical exams I and II to obtain the Specialist Certification Exam in Ophthalmology.
Methods:
A total of 46 valid questions from theoretical exam I and 122 from theoretical exam II were analyzed after the exclusion of 7 cancelled questions. The models were set to operate under standardized conditions, and their responses were compared with the official answer keys.
Results:
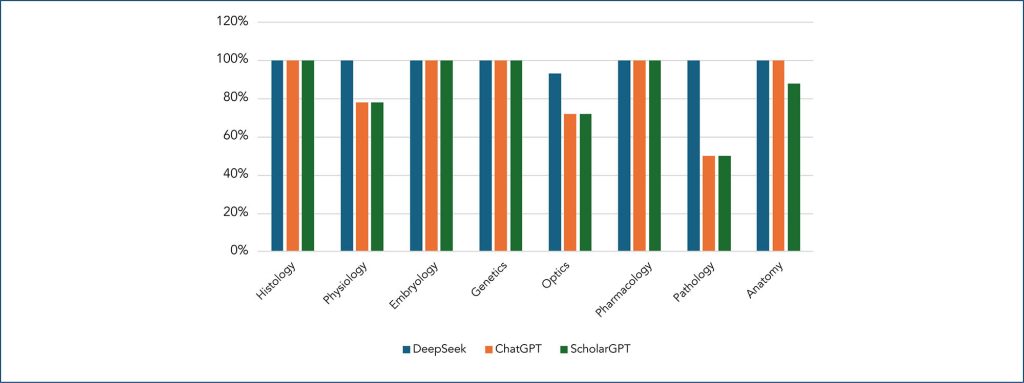
DeepSeek achieved the highest performance, with an accuracy rate of 97.8% in theoretical exam I and 81.9% in theoretical exam II, consistently outperforming the other models across all knowledge areas. ChatGPT demonstrated intermediate performance, while Scholar GPT had the lowest accuracy rate.
Conclusion:
The findings highlight DeepSeek’s superiority in highly specialized tasks, emphasizing the relevance of Artificial Intelligence models trained for specific technical domains. However, all models showed limitations in more complex questions, underscoring the need for human supervision in critical applications.